面向Flink的多表连接计算性能优化算法
首发时间:2019-12-03
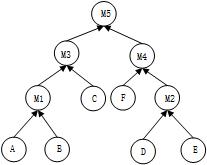
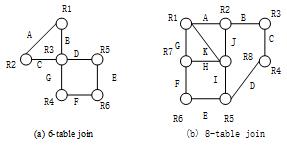
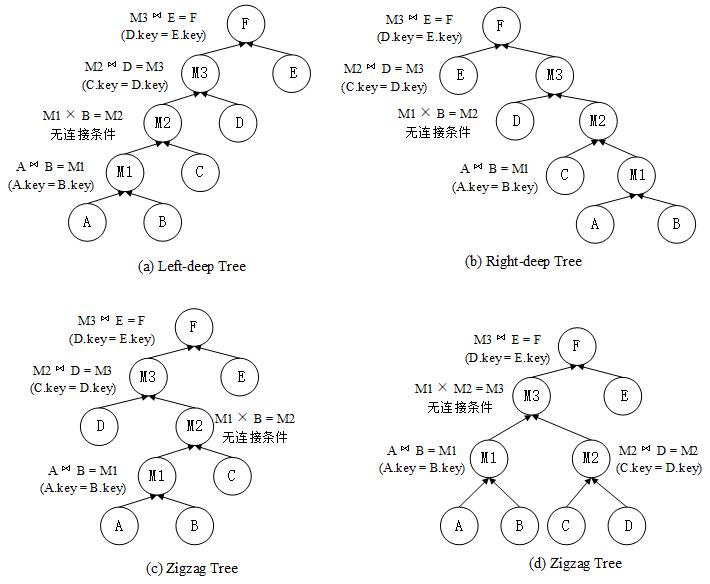
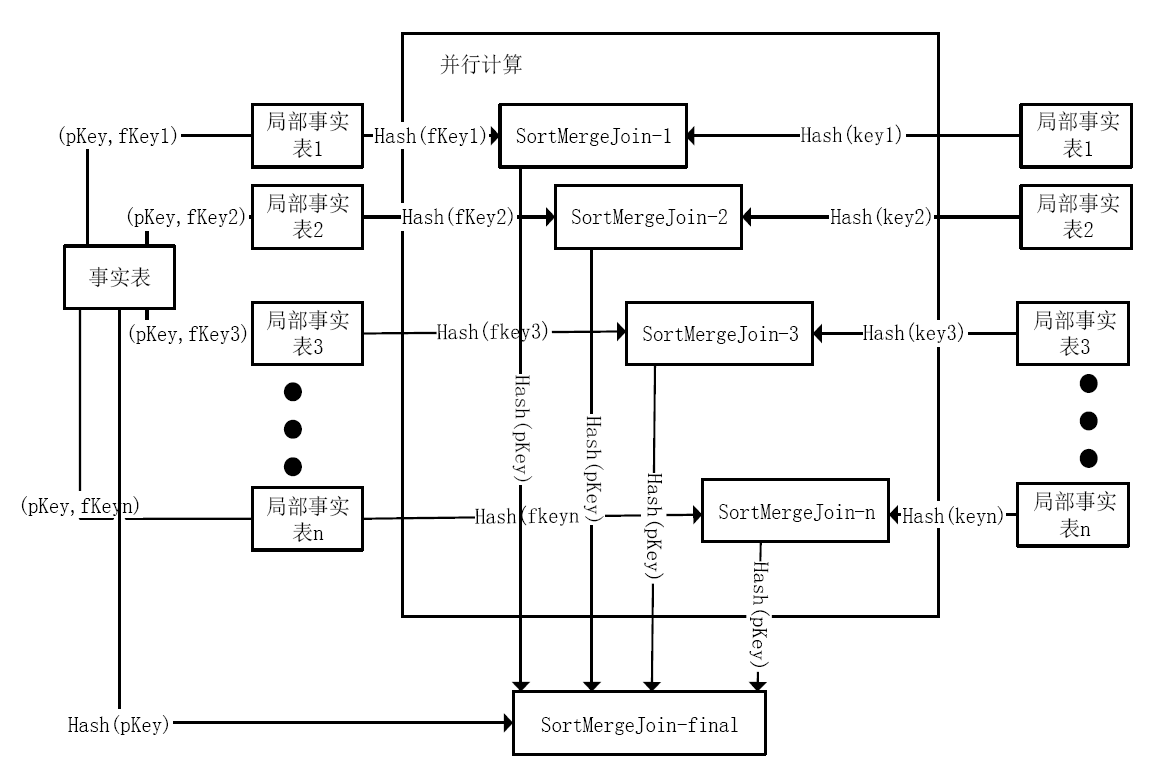
摘要:分布式计算引擎Flink已经被广泛应用到大规模数据分析处理领域,多表连接是Flink常见作业之一,因此提升Flink多表连接的性能能够加速数据处理和分析的速度。然而,直接将现有的多表连接优化算法应用到Flink上会带来两个问题:(1)现有算法不能充分发挥Flink基于线程的轻量级计算模型的性能优势。(2)连接算法需要shuffle的数据量过大。首先,提出了优化连接并行度的Multi Bushy Tree算法,尽可能提高多表连接计算的并行度。其次,提出了优化星型连接的Semi Join算法,可以大大减少需要shuffle的数据量。在TPC-H数据集实验结果表明提出的算法可以有效提高多表连接计算的并行度。缩短作业运行时间,减小星型连接中的网络IO代价。
关键词: 分布式处理系统 Flink 多表连接 连接并行度 数据混洗 连接顺序
For information in English, please click here
Computational Performance Optionmization Algorithm for Multi-table Joins Based on Flink
Abstract:Flink has been widely used in large-scale data analysis processing. Multi-table joins are one of the most common operations for data analysis, so improving the performance of Flink multi-table joins can speed up data processing and analysis. However, applying the existing multi-table join algorithm directly to Flink brings two problems: (1) The existing algorithm can not fully exploit the performance advantages of Flink\'s thread-based lightweight distributed computing. (2) The connection algorithm will cause great pressure on the network. Firstly, the Multi Bushy Tree algorithm for optimizing the parallelism of connections is proposed to improve the parallelism of multi-table join calculations. Secondly, the Semi Join algorithm for optimizing star connections is proposed, which can greatly reduce the amount of data that needs to be shuffled. In this paper, a lot of experiments are carried out on the large-scale dataset of TPC-H. The experimental results show that the proposed algorithm can effectively improve the parallelism of multi-table join calculation. Reduce job run time and reduce network IO cost in star connections.
Keywords: Distributed processing system Flink Multi-table join Parallelism of connections Data shuffle Connection order
论文图表:

引用


No.****
同行评议
共计0人参与
勘误表
面向Flink的多表连接计算性能优化算法
中国科技论文在线 版权所有
网站地图|
在线首页|
在线简介|
服务条款|
联系我们

京公网安备 11040202430024号 京ICP备15006316号-2| 网络出版服务许可证 (总)网出证(京)字第083号 | 文保网安备案号:1101080066



 .txt
.txt .ris
.ris .doc
.doc
评论
全部评论