基于字向量和BiLSTM-CNN的文本相似度计算方法
首发时间:2022-03-14
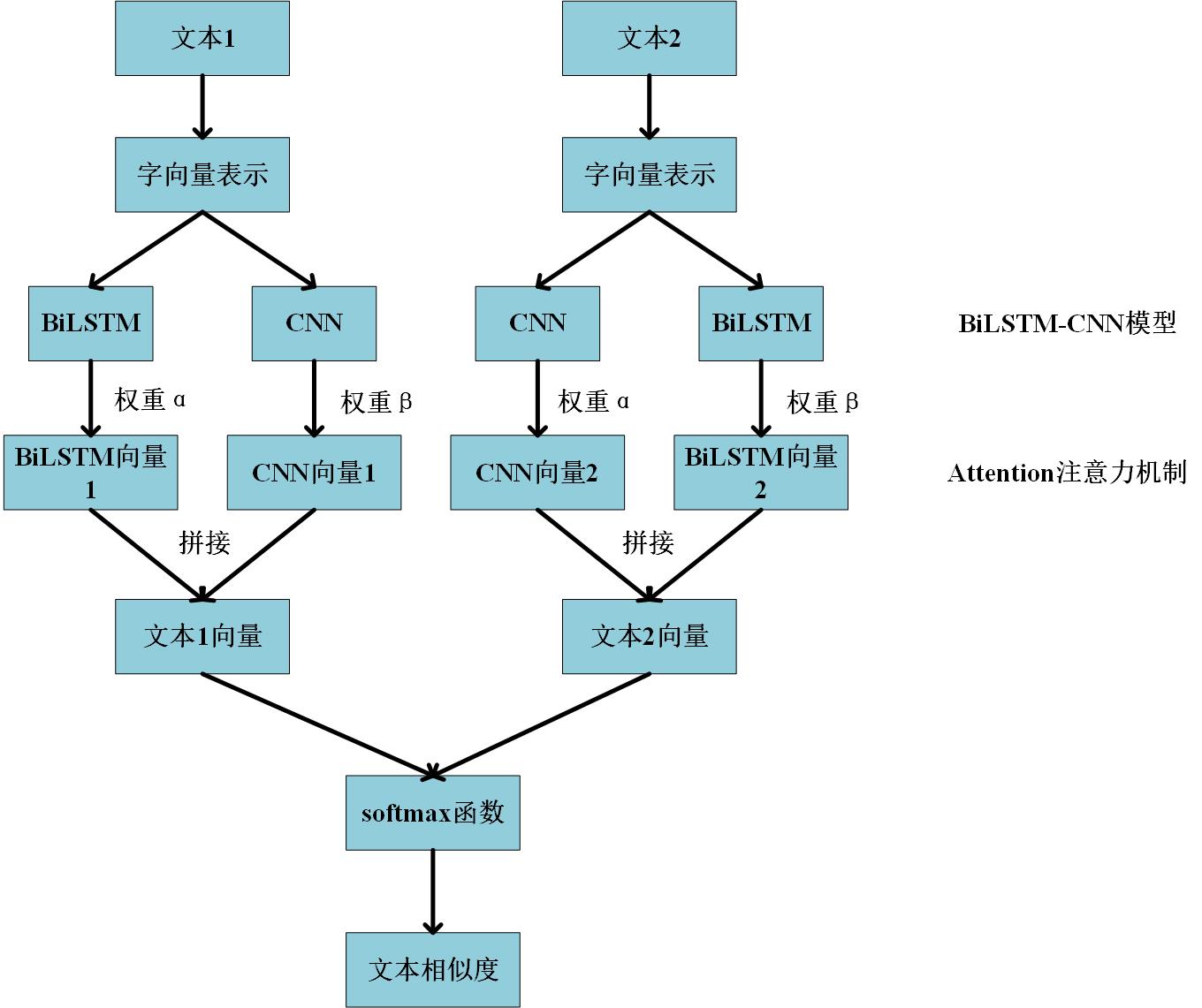
摘要:文本相似度在自然语言处理中有着重要的作用,随着对深度学习的研究,传统机器学习中出现的文本语义被忽略、人工获取文本特征时间长成本高等问题,都能很好地加以处理,然而在深层语义方面研究效果不是很理想。针对该问题,本文提出了一种基于字向量和BiLSTM-CNN的文本相似度计算模型。首先利用word2vec模型对文本进行训练,获得字向量集合;其次将文本通过字向量集合进行向量化表示,并输入到BiLSTM-CNN模型中,通过Attention进行拼接获得文本语义向量;最后采用softmax函数计算文本相似度。在Chinese STS数据集上进行验证和比较,最终表明该方法比其他模型的准确率更高。
关键词: 文本相似度 字向量 BiLSTM-CNN模型
For information in English, please click here
Text Similarity Calculation Method Based on Word Vector and BiLSTM-CNN
Abstract:Text similarity plays an important role in natural language processing. With the research of deep learning, the problems of text semantics being ignored in traditional machine learning, long time and high cost of manual acquisition of text features can be well dealt with. However, the effect of research on deep semantics is not very satisfactory. Aiming at this problem, this paper proposes a text similarity calculation model based on word vector and BiLSTM-CNN. First, the word2vec model is used to train the text to obtain the word vector set; secondly, the text is vectorized through the word vector set, and input into the BiLSTM-CNN model, and the text semantic vector is obtained by splicing through Attention; finally, the softmax function is used to calculate the text similarity. Validation and comparison on the Chinese STS dataset finally show that the method is more accurate than other models.
Keywords: text similarity word vector BiLSTM-CNN model
基金:
论文图表:
引用


No.****
动态公开评议
共计0人参与
勘误表
基于字向量和BiLSTM-CNN的文本相似度计算方法
中国科技论文在线 版权所有
网站地图|
在线首页|
在线简介|
服务条款|
联系我们

京公网安备 11040202430024号 京ICP备15006316号-2| 网络出版服务许可证 (总)网出证(京)字第083号 | 文保网安备案号:1101080066



 .txt
.txt .ris
.ris .doc
.doc
评论
全部评论